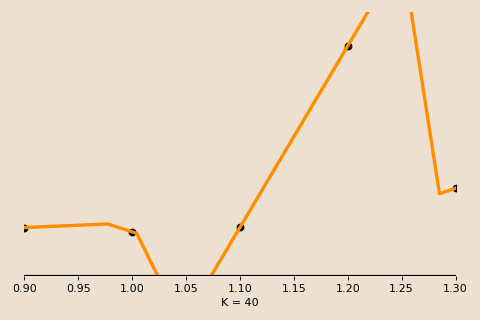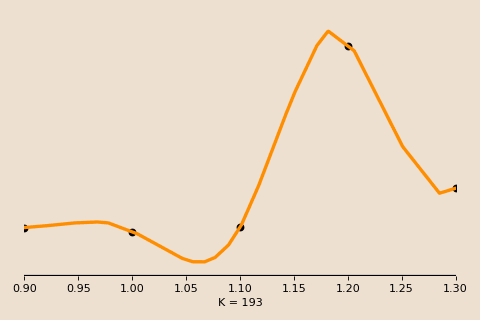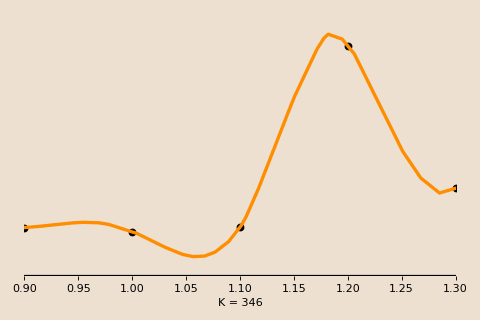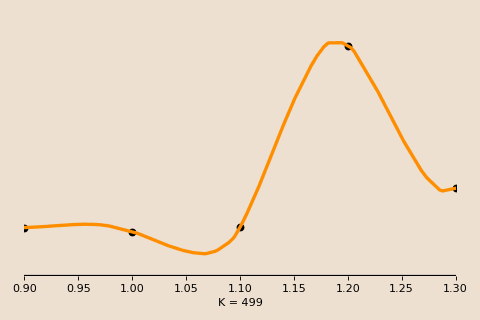
Plotting the training and testing error against some measure of model complexity (say, training time) for a typical case may look like in this figure, with both following the same decreasing direction and the test error hovering slightly above the train error.
Under the classical bias-variance tradeoff, as we move further right along the x axis (i.e. increasing the complexity of our model), we overfit and expect the test error to skyrocket further and further upwards even as the train error continues decreasing.
However, what we observe is quite different. Indeed the error does shoot up, but it does so before descending back down to a new minimum. In other words, even though our model is extremely overfitted, it has achieved its best performance, and it has done so during this second descent (hence the name, double descent)!
We call the under-parameterized region to the left of the second descent the classical regime, and the point of peak error the interpolation threshold. In the classical regime, the bias-variance tradeoff behaves as expected, with the test error drawing out the familiar U-shape.
To the right of the interpolation threshold, the behavior changes. We call this over-parameterized region the interpolation regime. In this regime, the model perfectly memorizes, or interpolates, the training data. That is, every model passes exactly through the given training data, thus the only thing that changes is how the model connects the dots between these data points.